
Abstract
We present LumiX, a structured diffusion framework for coherent text-to-intrinsic generation. Conditioned on text prompts, LumiX jointly generates a comprehensive set of intrinsic maps (e.g., albedo, irradiance, normal, depth, and final color), providing a structured and physically consistent description of an underlying scene.
This is enabled by two key contributions:
- Query-Broadcast Attention: A mechanism that ensures structural consistency by sharing queries across all maps in each self-attention block.
- Tensor LoRA: A tensor-based adaptation that parameter-efficiently models cross-map relations for efficient joint training.
Together, these designs enable stable joint diffusion training and unified generation of multiple intrinsic properties. Experiments show that LumiX produces coherent and physically meaningful results, achieving 23% higher alignment and a better preference score (0.19 vs. -0.41) compared to the state of the art. It can also perform image-conditioned intrinsic decomposition within the same framework.
Text-to-Intrinsic Generation Comparison

Both models are built upon FLUX. While IntrinsiX tends to overfit to specific indoor scenes, LumiX preserves FLUX's strong prior and produces consistent, high-quality intrinsic maps even for out-of-domain prompts.
Intrinsic Decomposition Comparison

LumiX performs intrinsic decomposition on in-the-wild data, producing albedo maps with less embedded lighting and generating consistent, high-quality intrinsic maps across all properties.
Method Overview
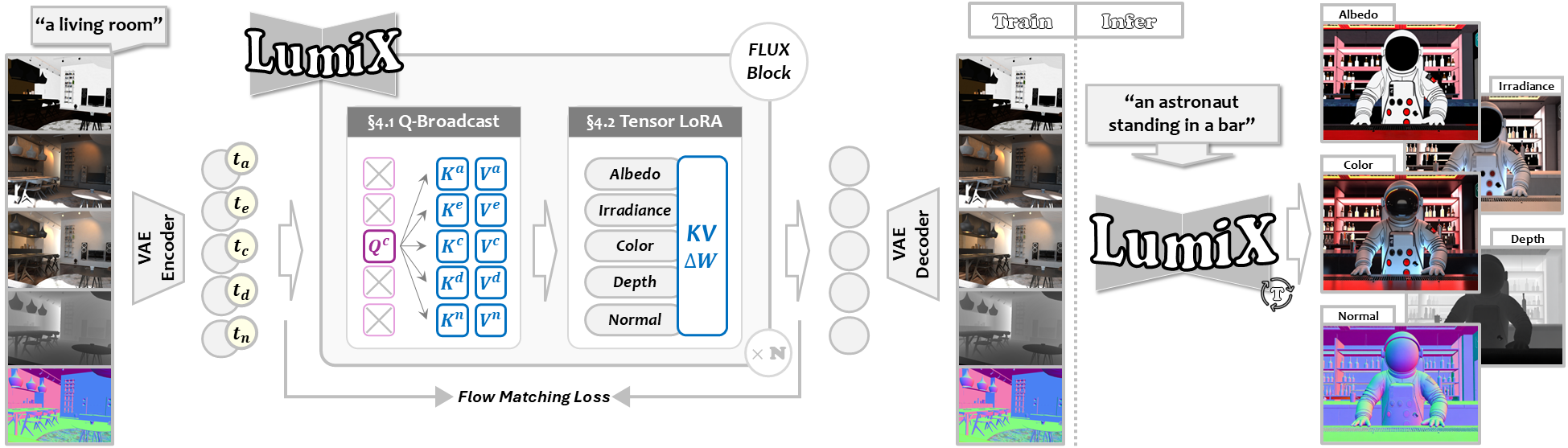
Overview of LumiX. Left (Training): Multiple intrinsic images are encoded and processed with Query-Broadcast Attention for pixel alignment and Tensor LoRA for efficient finetuning. Right (Inference): LumiX jointly outputs all intrinsic maps in a single forward pass, supporting both text-to-intrinsic generation and image-conditioned intrinsic decomposition.
Image-Conditioned Inference

Given a color image, LumiX performs intrinsic decomposition on Hypersim and in-the-wild data, and can further take albedo or irradiance as additional conditions. Conditioned images are shown with blue boxes.
Design Choice Comparison

Visual comparison of attention and LoRA designs. Vanilla attention with separate LoRA shows weak alignment. Our Tensor LoRA improves consistency, while Query-Broadcast Attention combined with Tensor LoRA achieves the best results, producing consistent and high-quality intrinsic maps across all properties.
More Text-to-Intrinsic Generation Results

Compared with IntrinsiX, LumiX yields higher-quality images and consistent intrinsic maps. Although trained at 512x512 resolution, LumiX can perform inference at arbitrary resolutions. Here shown at 1024x768.
More Intrinsic Decomposition Results

LumiX produces cleaner albedo maps with less embedded lighting and more accurate, consistent normal maps across diverse in-the-wild images, outperforming prior baselines.
Additional Examples

Robust decomposition of albedo, irradiance, and normal across diverse scenes and lighting conditions, demonstrating effectiveness beyond indoor environments.

LumiX produces high-quality albedo, irradiance, and normal maps on in-the-wild images, both indoor and outdoor scenes, with cleaner albedo (less baked-in lighting) and more accurate normals.

Consistent albedo, irradiance, and normal decomposition quality on various material types and complex real-world scenarios, showcasing strong generalization.
Citation
@inproceedings{han2026lumix,
title={LumiX: Structured and Coherent Text-to-Intrinsic Generation},
author={Han, Xu and Zhang, Biao and Tang, Xiangjun and Li, Xianzhi and Wonka, Peter},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21942--21952},
year={2026}
}